It just struck me that I thought wrong about what are ruby 3 goals are. So I want to summarize what Ruby 3 is about in this post for those who misunderstand it like me.
Ruby 3 has 3 main goals: Performance, Remove limits of GIL, Static type checker. And one big constraint: compatibility. Matz doesn’t want a repetition of Python 3 situation.
Sources: Ruby 3x3, Ruby 3.0 with Yukihiro “Matz” Matsumoto.
At some point, there started a fashion for UUIDs as primary key in the database. Maybe it happened after Jeff Atwood post.
So it is super nice to have a unique identifier as ID:
- you can generate it at the application level, no need to do a roundtrip to the database to get ID. I can imagine scenario in which complex data generated at application level, relationships between objects established at the same level and later all the data get stored in the database, like in the repository pattern
- you can have to disjoint database which can be later merged. I can imagine something like cockroachdb with instances in different continents, so one network roundtrip will be minimum 100ms (because of cosmic speed limit)
- it solves ID enumeration problem, but on the other side, UUID is too lengthy to use in URLs. Hexademical encoding (and 4 minuses) is not the most compact way to represent 128 bits, base64 or Base32 much more compact. hashids is another nice way to fight with enumeration and achieve compact IDs.
- UUID (virtually) is not just a unique identifier of a row in a table, but across the whole database (unless you have that huge DB, that you have collisions). This can be useful. On the other side given UUID alone, there is no way to understand what is the type of object. Some namespace in UUID would solve this issue. Also, other information can be embedded in UUID, like shard ID.
So far so good, but there are some cons:
- The main disadvantage is the performance of the unique index (binary trees do not like random values). But the solution for this is partially ordered UUID, for example
newsequentialid()in SQL Server or trick with GUID v1 described in this article. - bigger size, well 128 bits is only 4 times bigger than standard integers. That is not so bad, but… I saw database where UUIDs were stored as 36 chars, wait for it, utf-8 encoding. MySQL needs 3 times more size of the index for utf-8. Now, when most database support UUID natively, there should be less such of problems (MySQL, PostgreSQL)
ulid to save the day
ulid or Universally Unique Lexicographically Sortable Identifier is engineered to overcome all UUID disadvantages:
- it is lexicographically sortable, so should be much faster to insert in a unique index
- it has compact text representation (thanks to Base32), so much easier to handle and possible to use in URLs
- case insensitive and no special characters as a special bonus for usage with URLs
Other references
About OOP: You wanted a banana but what you got was a gorilla holding the banana and the entire jungle

photo credit: daily mail
I think the lack of reusability comes in object-oriented languages, not functional languages. Because the problem with object-oriented languages is they’ve got all this implicit environment that they carry around with them. You wanted a banana but what you got was a gorilla holding the banana and the entire jungle.
If you have referentially transparent code, if you have pure functions — all the data comes in its input arguments and everything goes out and leave no state behind — it’s incredibly reusable.
— Joe Armstrong, creator of Erlang, on software reusability. Source: Coders at Work.
But
Sending a message to an actor is entirely free of side effects such as those in the message mechanisms of the current SMALL TALK machine of Alan Kay and the port mechanism of Krutat and Balzer.
— Carl Hewitt (et al.) author of Actor model. Source: A Universal Modular ACTOR Formalism for Artificial Intelligence
The actor model is one of the basic ideas behind Erlang [citation required]. SmallTalk is first OOP language, (or second if you count Simula). Alan Kay coined term OOP. I saw a paper where Carl Hewitt explicitly stated that Actor model was inspired by SmallTalk, but I can not find it at the moment.
See also:
Algorithms + Data Structures = Programs
— Niklaus Wirth
Books
- Algorithms, by Robert Sedgewick and Kevin Wayne (also referred as Sedgewick)
- The Algorithm Design Manual (pdf), by Steven Skiena (also referred as Skiena)
- The Art of Computer Programming, by Donald E. Knuth (also referred as TAOCP)
- Introduction to Algorithms, by Cormen, Leiserson, Rivest, and Stein (also referred as CLRS)
- Algorithms, by Dasgupta, Papadimitriou, and Vazirani (also referred as Dasgupta);
- Structure and Interpretation of Computer Programs, by Harold Abelson and Gerald Jay Sussman with Julie Sussman (also referred as SICP)
- Purely Functional Data Structures, by Chris Okasaki (also referred as Okasaki)
- Algorithms, Etc., by Jeff Erickson
- Algorithms and Data Structures, N. Wirth
| Prose | Code | Code details | Math | Breadth and Depth | Price | |
|---|---|---|---|---|---|---|
| TAOCP | 1🏆 | 3 | MIX assembly, pseudocode | 1🏆 | 1🏆 | $$$$ |
| Skiena | 2 | 1🏆 | pseudocode, C | 4 | 3 | Available for free |
| Dasgupta | 3 | 2 | high-level pseudocode that resembles Pascal | 3 | 4 | $ |
| CLRS | 4 | 2 | high-level pseudocode that resembles Pascal | 2 | 2 | $$ |
Table based on A Comparison of Four Algorithms Textbooks. See also: ALGORITHMS AND DATA STRUCTURES BOOKS: ONE SIZE DOESN’T FIT THEM ALL
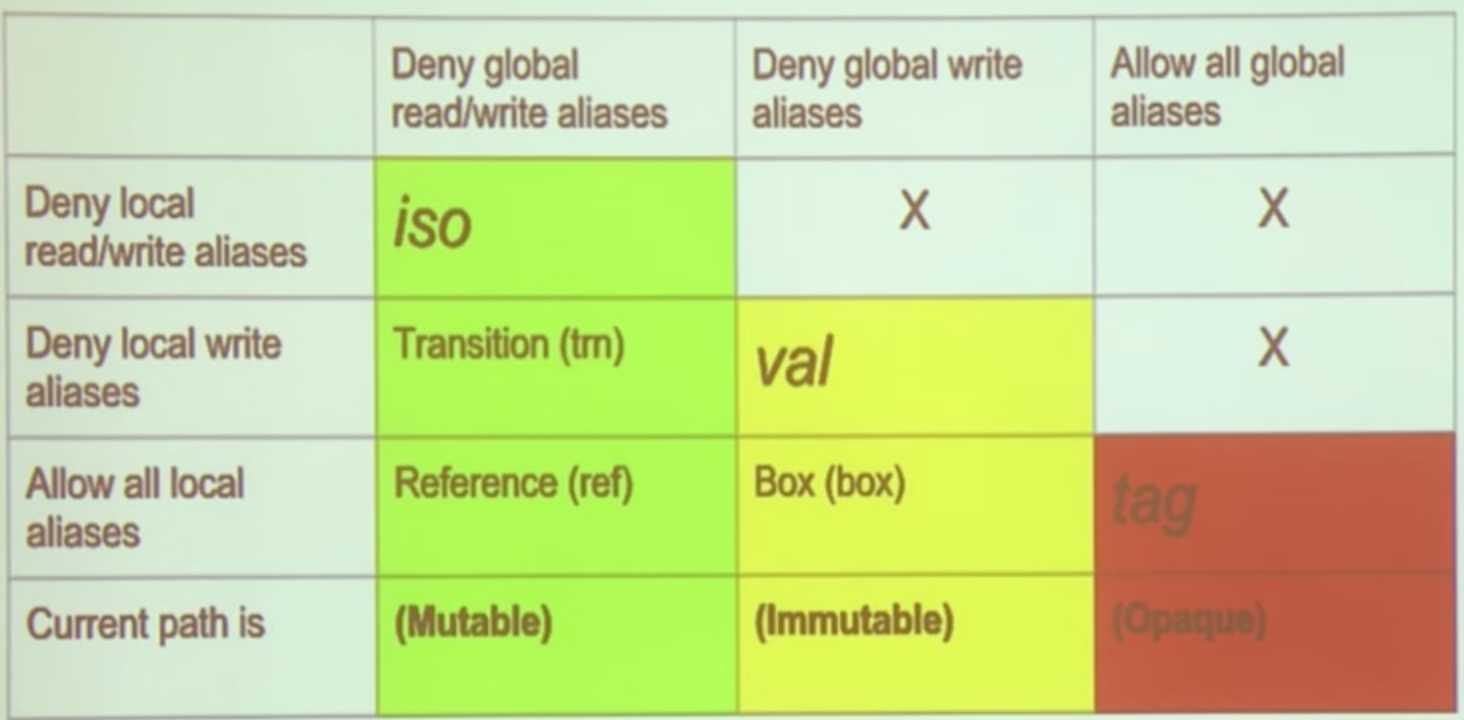
Screenshot from this talk about Pony language.
It is well known that only prefix searches work good for LIKE queries (LIKE "abc%"), but not for suffix queries (LIKE "%abc%"). This happens because of databases often use B-Tress indexes for text data. There are also full-text search capabilities in some databases, but this is not the same as pattern matching search with LIKE. What to do if you need suffix search? Depends on the case.
Suffix only search - LIKE "abc%"
If you need only suffix search, but not both - solution is simple. Create an additional column with reversed data and use prefix search LIKE "%cba".
Detect beginning of a search term
If you can detect the beginning of a search term you can reduce LIKE "%Abc%" to LIKE "Abc%". For example, if you have columns with phone numbers and user searches for +123456789, you know that + is the start of the phone number and it can not be in the middle of a word. The same can be done for capital letters and names, unless you have Irish names, like McDouglas.
Trigram index
PostgreSQL supports trigram indexes. With trigram indexes you can search for LIKE "%abc%" effectively, trade off is a huge size of the index.

TL;DR I need React component for maps. I thought it would be easy. The 5-minute task, not more. As a result, it turned out to be month (not a month of working time) trip of errors, trials and bug reports.
Google maps
Obviously, I tried react-google-maps. I didn't know much about maps and React at the moment. Immediately got a bug with rendering popup (infoWindow in terms of Google Maps). I found out that this library poorly supported and started to search for alternatives. There are 4 alternatives for React Google maps components. But all of them poorly supported.
See full table with data in my gist
A collection of links useful for open-source projects.
- Open Source Guides
- Retina-ready badges
- Tools for Open Source by Github
- repostatus.org
- issuestats.com
- github-stats-collector
More badges:
- https://badge.fury.io/
- https://github.com/badges/badgerbadgerbadger
- https://github.com/dwyl/repo-badges
- https://glebbahmutov.com/blog/project-status-badges/
Share buttons:
- http://sharingbuttons.io/
- https://github.com/igrigorik/hackernews-button
Demos:
- https://asciinema.org/
- OS X Screencast to animated GIF
TL;DR Let’s suppose your application needs some kind of reference data, for example, names of all countries or currencies or time zone, you have two options:
- copy data from open source to your application and work with it directly
- use third-party dependency (library, npm package, ruby gem etc) which will provide this data
The second approach is a good choice: you get versioning, community support, bugfixes.
Track problem
Use some kind of monitoring solution to track server perfomance. You can choose from something more general, like Nagios, NewRlic or Stackdriver, to something specifilly tailored for Rails like Skylight or Scout.
Narrow down source of a problem
N+1 problem
Easy to fix when you know you have one. Use Skylight or Bullet to detect it. You also can discover it from rack-mini-profiler or RailsPanel.
Slow queries
Use the index, Luke. Use Skylight or DBs slow queries log to detect a problem.
Ruby arguments evaluated on function call. So if you have default arguments like this a = {} it means Ruby will create new object for every call without arguments. Lets see in action:
Example 1:
$ irb
> def test_hash(a={}); end
v1 = ObjectSpace.count_objects
10000.times{ test_hash }
v2 = ObjectSpace.count_objects
v2[:T_HASH] - v1[:T_HASH]
=> 10015
exit
In first example Ruby created 10000 anonymous hashes which will be sweeped on the next GC run. But do you want to make a job for it in first place? And then they complain about GC pauses :/
Example 2:
$ irb
> def test_nil(a=nil); end
v1 = ObjectSpace.count_objects
10000.times{ test_nil }
v2 = ObjectSpace.count_objects
v2[:T_HASH] - v1[:T_HASH]
=> 18
exit
$ irb
> EM_HASH = {}.freeze
def test_hash2(a=EM_HASH); end
v1 = ObjectSpace.count_objects
10000.times{ test_hash2 }
v2 = ObjectSpace.count_objects
v2[:T_HASH] - v1[:T_HASH]
=> 19
exit
No anonymous hashes.
Different ways to define factorial function. Using it because it is good example of recursive function.
Empathy, cooperation, fairness and reciprocity — caring about the well-being of others seems a very human trait. But Frans de Waal shows several surprising videos of behavioral tests with primates and other mammals, that show how many of these moral traits all of us share.
This is argument against idea that morality comes from religion. Morality can be result of evolution for better survival of social groups.
See also: Moral machine.
Functional way e.g. Lambda calculus
true = λx.λy.x
false = λx.λy.y
if a then b else c = a b c
For example:
if true then b else c → (λx.λy.x) b c → (λy.b)c → b
if false then b else c → (λx.λy.y) b c → (λy.y)c → c
Translate to JavaScript (ES6)
const True = (x) => (y) => x
const False = (x) => (y) => y
const b = 1 // you can use `()=>1` to get more functional attitude
const c = 2
let a = True
a(b)(c) // returns 1
a = False
a(b)(c) // returns 2
Bonus points: Lisp if
(if true-or-false-test
action-to-carry-out-if-the-test-returns-true
action-to-carry-out-if-the-test-returns-false)
Note: Lisp corresponds to an untyped, call-by-value lambda calculus extended with constants.
Translate to JavaScript (ES6)
const ifThenElse = (test, thenAction, elseAction) => test(thenAction)(elseAction)
ifThenElse(True, 1, 2) // returns 1
ifThenElse(False, 1, 2) // returns 2
OOP way e.g. SmallTalk/Ruby
Code partially taken from Yehuda’s post. It is in ruby, which can be considered SmallTalk reincarnation.
class TrueClass
def if_true
yield
self
end
def if_false
self
end
end
class FalseClass
def if_true
self
end
def if_false
yield
self
end
end
# returns value
if a
b
else
c
end
# prints value
(a).
if_true { puts b }.
if_false { puts c }
Translate to JavaScript (ES6)
const True = Object.create({
ifTrue: (callBack) => {
callBack.call()
return this
},
ifFalse: (callBack) => {
return this
}
})
const False = Object.create({
ifTrue: (callBack) => {
return this
},
ifFalse: (callBack) => {
callBack.call()
return this
}
})
const b = ()=>{ console.log(1) }
const c = ()=>{ console.log(2) }
let a = True
a.ifTrue(b).ifFalse(c) // prints 1
a = False
a.ifTrue(b).ifFalse(c) // prints 2
Is Mathematics invented or discovered?
This idea comes from paper “Propositions as Types” by Philip Wadler.
Philosophers might argue as to whether mathematical systems are ‘discovered’ or ‘devised’, but the same system arising in two different contexts argues that here the correct word is ‘discovered’.
— Philip Wadler
Wadler amazed by the fact of similarities between different branches of science, like logic and type systems (Curry-Howard correspondence) and topology (Homotopy Type Theory and Univalent Foundations) and objects of a Cartesian closed category (Curry-Howard-Lambek Correspondence) etc.
So we can think of it as laws of nature being rediscovered again and again in different context (Wadler’s idea) or it is our brain which recognizes same patterns again and again in different context (my addition).
There is other interesting paper called “Physics, Topology, Logic and Computation: A Rosetta Stone” which adds quantum mechanics (QM) to “equation”. And here things getting even more interesting. Are there basic set laws of nature at level of quantum mechanic, which reappears in different science areas? Can we explain everything using QM?
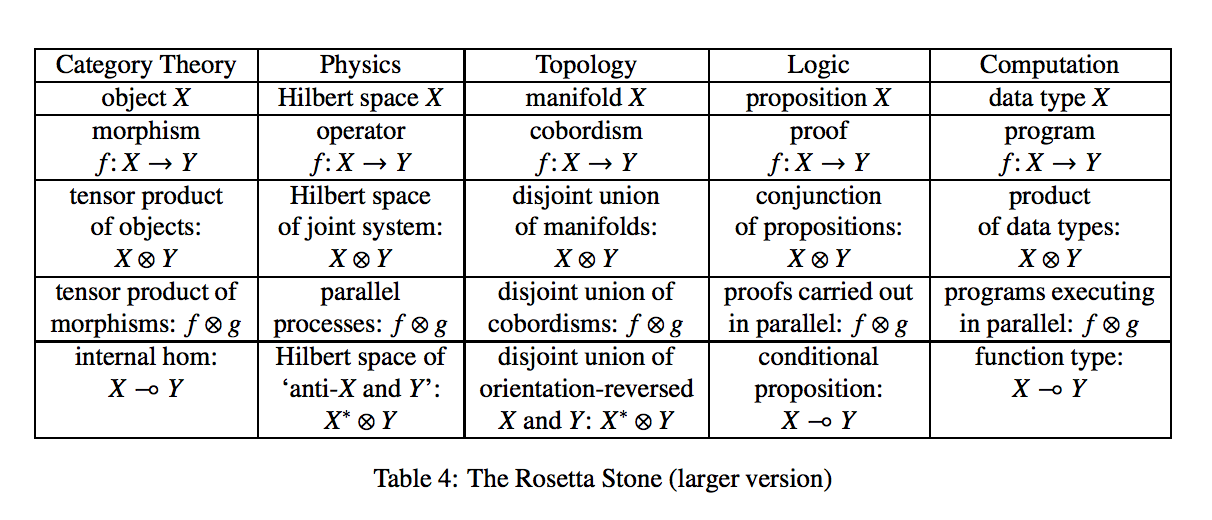
Side note: there are some fields of logic and type calculus which does not have correspondence yet, generally believed that correspondence yet to be found.
Quantum Mechanics vs General Relativity
One more obstacle in the direction of unifying everything with QM is the fact that relativistic physics and QM considered to be incompatible. But there is attempt to fix this - see Space Emerging from Quantum Mechanics. There are also other works which links classical physics and QM, for example classical chaos theory. See also “There are no particles, there are only fields”.
Interesting questions arise can we describe basic laws of QM and derive all other laws of nature from them using purely mechanical way of reasoning as in Turing Machines? According to Godel if this system of rules is consistent as number theory we can not derive all truth. If we can construct simulation program based on this laws can we predict future, can we deduce what happened before? Are there physical limits that will prevent for such program (machine) to work, like uncertainty principle? Does halting problem corresponds to some limitations aroused by physics. Side note: Ultimate physical limits to computation.
Can we actually discover basic rules?
Other question if universal basic laws of QM reveal actual nature of universe or is it just the limit of our perception? Like example in “Real patterns”, where epiphenomena of movement appears in Conway’s game of life even though it is never meant to be that way, there are simple rules which describe Conway’s universe and it has nothing to do with movement. Even more disturbing is the fact that you can construct Turing Machine e.g. and represent a lot of things that TM can do in Conway’s game of life or self-replicating structure which reminds idea of DNA.
Computer science is a terrible name for this business. First of all, it’s not a science. It might be engineering or it might be art, but we’ll actually see that computer so-called science actually has a lot in common with magic… So it’s not a science. It’s also not really very much about computers. And it’s not about computers in the same sense that physics is not really about particle accelerators, and biology is not really about microscopes and petri dishes. And it’s not about computers in the same sense that geometry is not really about using surveying instruments.
— Hal Abelson
First lecture of 6.001 Structure and Interpretation of Computer Programs:
Mathematics is the science of formal systems.
What is computation?
According to Leslie Lamport computation is what computational device (or human - my addition) does. It doesn’t matter if it is “useful” calculation or simple bits flipping. More formal way to define computation is to view it as sequence of state mutations.
There is other wide used way to think of computation: functions. Mathematical function maps some input value to some output value. But mathematical function doesn’t care how you get from input to output, but for computation it is big deal. Otherwise there would be no bubblesort, quicksort or other sort algorithms. Computable mathematical function is expected to have output value e.g. halt, while computation can be infinite, think of clock or OS.
Type of errors by nature
Notice: this classification lacks of formal proof. While first two categories clearly defined, other is more hand-wavy explained and contains all errors, that are not fail in first two categories.
Undefined value
Humankind doesn’t know answers to those questions yet. Generally possible those questions are undecidable.
Example: division by zero, factorial of negative number, etc.